Zipfs law and my ineptitude, part deux
Sometime ago I tried my hand at proving Zipfs law using Saint Thomas Aquainas Summa Theologia. The attempt was a complete failure, so I wanted to try again (once bitten, twice shy, and you don’t grow up to be a nerd).
This time however I went with Kotlin (an awesome new language for the Java virtual machine) and War and Peace, the classic Russian novel (which I got for free from Project Gutenberg).
If Zipfs law holds, then we should see a blue line falling straight and a red line (which is the frequency of the word, multiplied with the relative position of the word) staying almost constant, but as can be seen in the graph, this is not the case, not by a long shot. If we just use the to 100 words the average frequency is 3107, the average adjusted frequency, divided by the total adjustment, is 1427, which means the average frequency is more than twice what it should be.
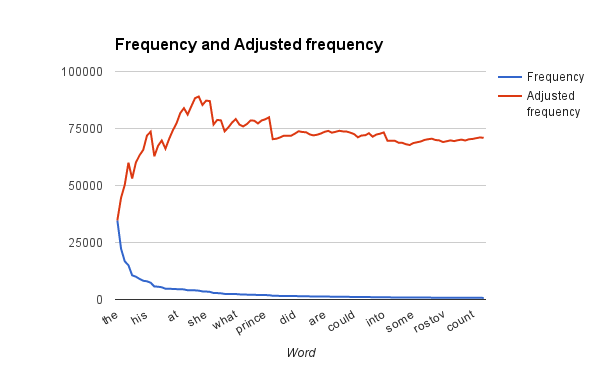
Even worse for my self-esteem, it doesn’t look like there is a bug in the program as the top ten words are: the and to of a he in that his was. Given that the main person is a male (and at least the couple pages that I read) talks about him in the first person, I don’t think those are unrealistic.
Okay so Tolstoy isn’t British, perhaps if I had used the original Russian it would have been different – but looking in to it, a significant part of the novel is actually in French. Oh well. Lets try with something completely different: Anna Karenina.
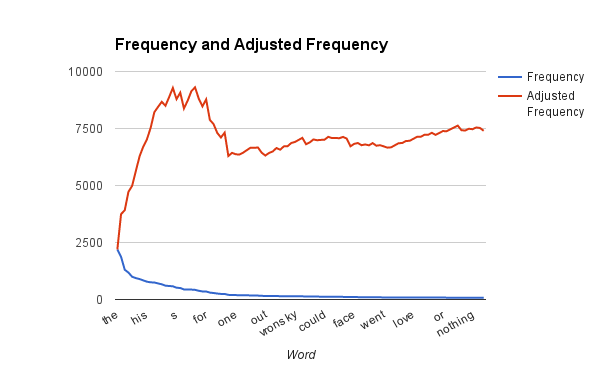
Still no luck. If Zipfs law holds then we would expect to see the ratio of the average unajusted word over the average adjusted word devided by the adjustment to be one (ie they cancel out) but that isn’t the case for either of the two, so I went ahead and downloaded the top ten books from project Gutenberg. These are the ratios I found:
| Title | Ratio |
|---|---|
| The Adventures of Huckleberry Finn | 1.9992198058099362 |
| Alice Adventures in Wonderland | 1.9851261916381613 |
| Anna Karenina | 2.0704857183257914 |
| Beowulf | 2.201444236037978 |
| Frankenstein | 2.384831717351647 |
| The Metamorphis | 1.9659961377948403 |
| Moby Dick | 2.1206125367045408 |
| Pride and Prejudice | 1.9197390080077206 |
| The Adventures of Sherlock Holmes | 2.070056679992902 |
| The Legend of Sleepy Hollow | 2.4493014749970023 |
| The Yellow Wallpaper | 2.0006322162974524 |
| War and Peace | 2.177793662470332 |
The only possibly remarkable thing here is that the ratio seems to hover around 2.
By digging into Google Scholar I found this old article (pdf link warning), where the author is nice enough to count his own words and their frequency out (check the link for the data, the link will open in a separate window or tab), which caused me to take another look at my data: the graphs and numbers do actually fit relatively nice, once you discount the top 7 or so words.
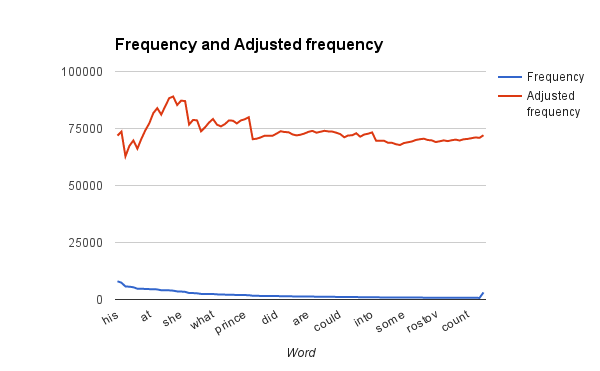
Thank you. Thats the kinda of data we would expect to see. I guess when you cut the outliers, the theory fits the data beautifully.